Всем программистам известно, что правильное форматирование облегчает чтение кода. И расстановка отступов — одна из самых важных задач при форматировании текстов программ. Отступы позволяют увидеть общую структуру кода, просто просмотрев его «по диагонали». Благодаря им можно быстро перейти к нужному блоку. Думаю, никто с этим спорить не будет. Но при форматировании кода иногда возникают вопросы, не имеющие единственно правильного ответа. Один из таких вопросов — «Что использовать для отступов: символы табуляции или пробелы?».
У символов табуляции свои преимущества:
- Символы табуляции занимают меньше места в исходном тексте программы. (Правда, в наше время это редко бывает актуальным; скорость процессоров и объём дисков выросли настолько, что для абсолютного большинства программ разница будет просто незаметна.)
- По отступам, состоящим из символов табуляции, можно быстрее перемещаться. Такие отступы и удалить можно гораздо быстрее. Для этого просто нужно меньше нажатий клавиш.
- Ширина символа табуляции настраивается в большинстве текстовых редакторов. Т.е. каждый человек, который будет читать Ваш код, сможет настроить, как у него будут отображаться отступы, в соответствии со своими предпочтениями и размером монитора.
Преимущества есть и у пробелов:
- В программном коде отступ начала строки от левого края экрана зависит не только от уровня вложенности блока, к которому эта строка относится. Иногда нужно выровнять первый символ строки относительно какого-нибудь символа в предыдущей строке. Такая ситуация, как правило, встречается при разбиении одной длинной инструкции на несколько строк. Такую «тонкую» настройку нельзя делать символами табуляции. Для этого вида форматирования подходят только пробелы. Если отступы, показывающие уровень вложенности блока, создаются с помощью символов табуляции, а более «тонкое» выравнивание делается с помощью пробелов, то возникает путаница. Программист должен постоянно внимательно следить, какой символ нужно использовать. Это, мягко говоря, не всем нравится. Особенно остро проблема встаёт перед большими командами разработчиков.
- Символ табуляции выглядит так же, как один или несколько пробелов, но ведёт себя по-другому. Быстро понять, где в коде пробелы, а где табуляция может быть не просто.
Многие из описанных проблем могут решаться «умными» текстовыми редакторами. Особенно продвинутыми являются редакторы, специально созданные для работы с программным кодом. Если такой редактор «знает» синтаксис языка программирования, он пытается «понять», что именно Вы хотите сделать, и автоматически отформатировать код согласно заданным настройкам. Разумеется, даже самый «умный» редактор кода может ошибаться и неправильно понимать намерения программиста. Но программы этого типа становятся всё лучше и уже помогли множеству программистов сделать их работу комфортнее. Настройки, регулирующие работу с пробелами и символами табуляции, имеют не только текстовые редакторы. Они есть во многих других инструментах для работы с программным кодом (например, в системах контроля версий).
В этом посте я хочу описать настройки MS Visual Studio, регулирующие работу с пробелами и символами табуляции. В первую очередь нужно в главном меню выбрать пункт Tools->Options. Откроется окно Options. В его левой части расположено древовидное меню в нём нужно выбрать пункт TextEditor->AllLanguages->Tabs. Там находятся настройки отступов, которые действуют для всех языков программирования и разметки, поддерживаемых MS Visual Studio. Если требуется изменить настройки только для конкретного языка, то в дереве слева вместо пункта AllLanguages следует выбрать нужный язык (см. рисунок 1).
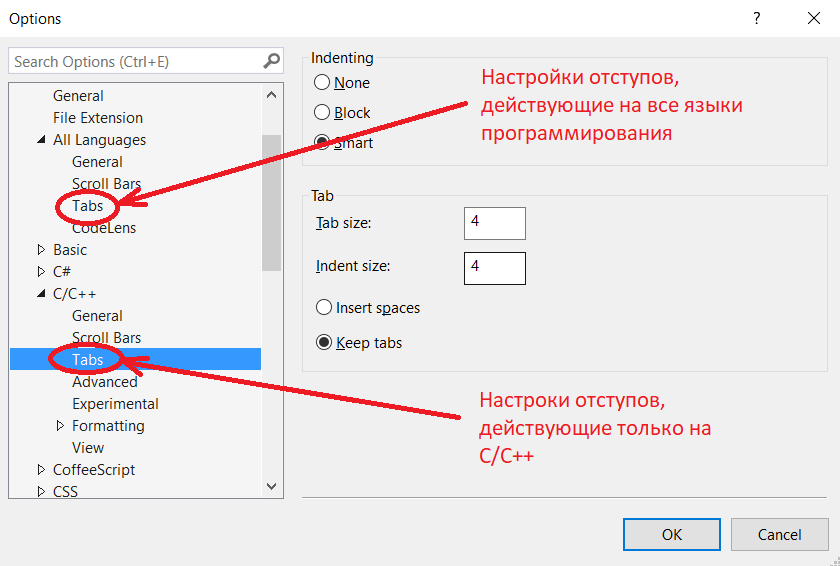
Пункт Tabs существует для каждого языка. Если для разных языков установлены разные параметры табуляции, то на странице AllLanguages->Tabs будет показано сообщение о том, что параметры табуляции для разных текстовых форматов конфликтуют друг с другом. («The tab settings for individual text formats conflict with each other.») После того, как он был выбран, в правой части окна появятся две группы настроек: Indenting и Tab. Все настройки, которые определяют, какого размера должны быть отступы, и из каких символов они должны состоять, находятся в группе Tab. (см. рисунок 2).
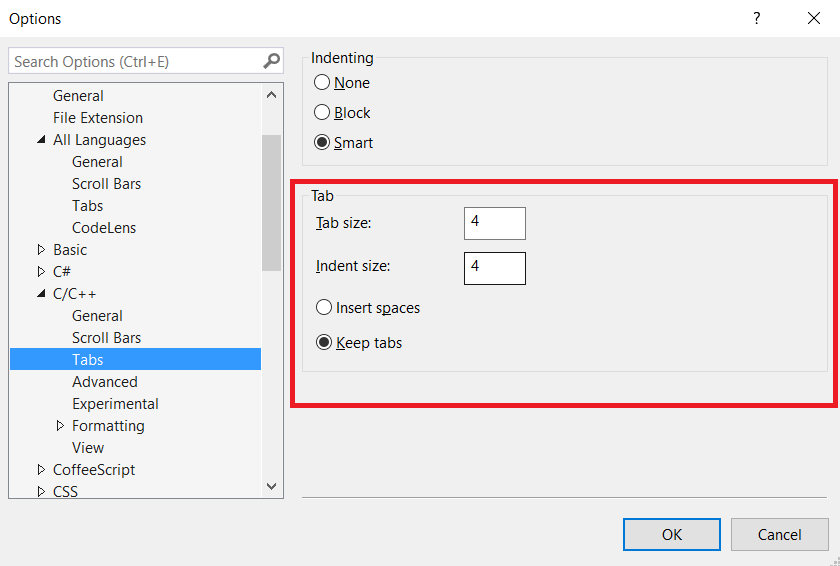
Рассмотрим подробно каждый параметр из этой группы:
- Tab size — это размер интервала табуляции. Он задаёт расстояние между позициями табуляции в пробелах. Проще говоря, этот параметр определяет, какому количеству пробелов равен один символ табуляции.
- Indent size — это размер автоматического отступа в пробелах. Для заполнения указанного размера отступа могут использоваться символы табуляции, символы пробела или оба этих вида символов. Что именно будет использовано, зависит от того, какая из следующих 2 радиокнопок выбрана.
- Insert spaces — вставлять только пробелы. Когда выбран этот параметр, отступ будет всегда состоять только из пробелов. Причём неважно, каким способом отступ создаётся: его автоматически вставляет текстовый редактор IDE, пользователь нажимает клавишу «Tab» или кнопку «Increase Indent» на панели инструментов.
- Keep tabs — сохранять символы табуляции. Когда выбран этот параметр, для создания отступа используется максимально возможное число символов табуляции. Символ табуляции вставляет такое число пробелов, которое указано в поле «Tab size». Если размер отступа не кратен размеру интервала табуляции, для заполнения разницы добавляются знаки пробелов.
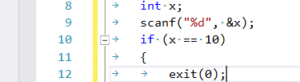
Ещё одна полезная возможность — показ на месте знаков табуляции и пробела специальных символов. Это позволяет с первого взгляда отличать эти символы друг от друга. Эту настройку можно найти в меню Edit->Advanced->ViewWhiteSpace. Ещё один способ включить/выключить отображение пробельных символов — это использование «горячих клавиш». Последовательное нажатие сочетаний клавиш Ctrl+R, Ctrl+W включит отображение пробельных символов, если оно было выключено. Если отображение пробельных символов было включено, то та же комбинация «горячих клавиш» его выключит. Пробел будет показан как точка на уровне середины строки, а начало каждого интервала табуляции будет обозначено стрелочкой (см. рисунок 3).
Я использовал MS Visual Studio 2015, но показанные настройки должны работать и в более новых, и в более старых версиях.